
kafka整合
一、kafka背景
Kafka 是一种分布式流处理平台,最初由LinkedIn开发,并于2011年成为Apache软件基金会的顶级项目。它提供了高吞吐量、可扩展性和持久性的消息发布和订阅系统。
场景
日志收集与聚合:
Kafka 可以作为日志收集系统的核心组件,帮助将分布在不同服务器和应用程序中的日志数据集中存储和处理。
它支持高吞吐量的日志传输,并具备可靠性、持久性和容错性,适用于大规模的日志处理需求。
实时流处理:
Kafka 作为消息传递平台,可以与实时流处理框架(如 Apache Flink、Apache Spark Streaming)结合使用,实现实时数据的流式处理和分析。
实时流处理场景包括实时数据管道、实时报警监控、实时指标计算等。
数据集成与异步通信:
Kafka 可以用于不同系统之间的数据集成和解耦,通过发布-订阅模型进行异步通信。
例如,将产生的事件或变更记录发布到 Kafka 主题中,然后其他系统订阅这些主题来获取相关数据,实现系统之间的解耦和灵活性。
系统解耦与削峰填谷:
使用 Kafka 可以将不同的业务模块解耦,降低系统之间的依赖性。
同时,Kafka 的高吞吐量特性可以帮助应对流量峰值,通过削峰填谷的方式平滑处理系统的压力。
消息队列与任务调度:
Kafka 可以作为可靠的消息队列,在分布式系统中实现任务调度和消息传递。
它支持消息的持久化存储、批量处理和消费者组管理,适用于异步任务处理、事件驱动架构等场景。
概念
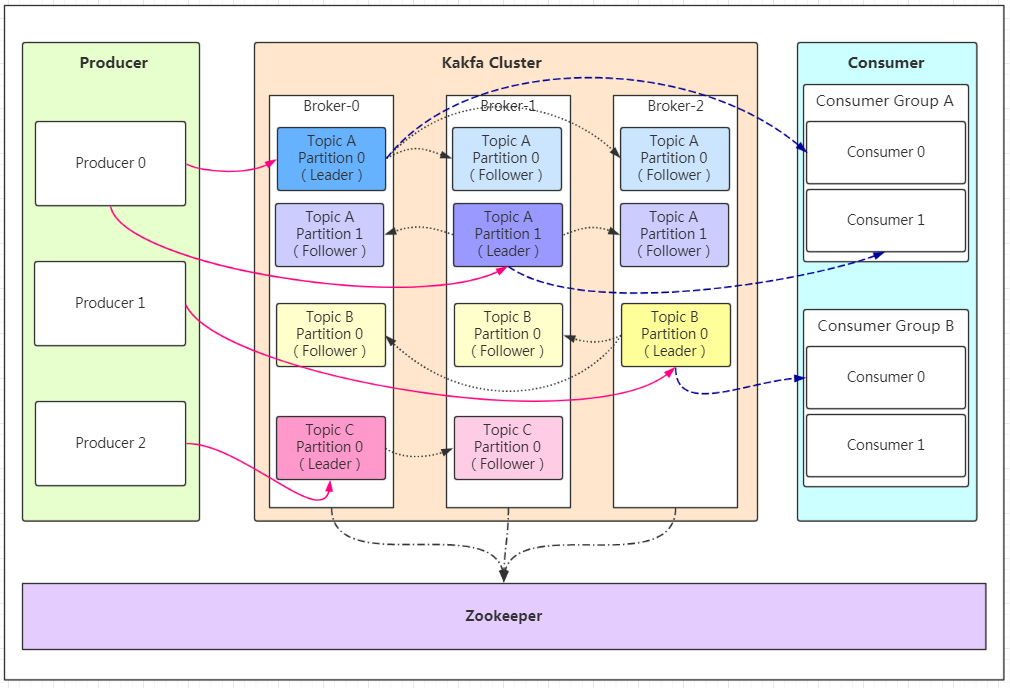
Broker(代理):
每个运行中的 Kafka 服务器节点称为 Broker。
Broker负责接收来自生产者的消息并将其存储在磁盘上,同时为消费者提供订阅和拉取消息的服务。
Topic(主题):
主题是消息的逻辑分类单元,每条发布到 Kafka 的消息都有一个特定的主题。
主题可以被分成一个或多个分区,并且可以在 Kafka 集群中进行分布。
Partition(分区):
主题可以被划分为多个分区,每个分区是一个有序、不可变的消息序列。
分区允许数据的水平扩展和并行处理,并且还支持副本机制以提供容错性和高可用性。
Producer(生产者):
生产者负责向 Kafka 的主题发送消息。
生产者可以选择将消息发送到特定的分区,也可以依靠 Kafka 的负载均衡算法自动选择分区。
Consumer(消费者):
消费者是从 Kafka 主题订阅消息并处理它们的应用程序。
消费者以消费者组的形式存在,每个分区只能由同一消费者组内的一个消费者来消费。
Consumer Group(消费者组):
多个消费者可以组成一个消费者组,共同消费主题中的消息。
消费者组允许实现消息的并行处理和水平扩展,并确保每条消息只被消费者组中的一个消费者处理。
Offset(位移):
Offset 是指每个分区中消息的唯一标识符或偏移量。
消费者在读取分区的消息时会跟踪位移,以确定下一条要读取的消息位置。
Replication(副本):
Kafka 使用副本机制来提供数据冗余和容错性。
每个分区可以有多个副本,其中一个是领导者负责处理客户端请求,其他副本是追随者用于备份数据。
Commit(提交)和 Acknowledgement(确认):
消费者在成功消费一条消息后,需要将消费的位移提交给 Kafka。
提交位移可以同步或异步进行,并且消费者可以根据返回的确认信息判断是否提交成功。
通信模式
点对点模式
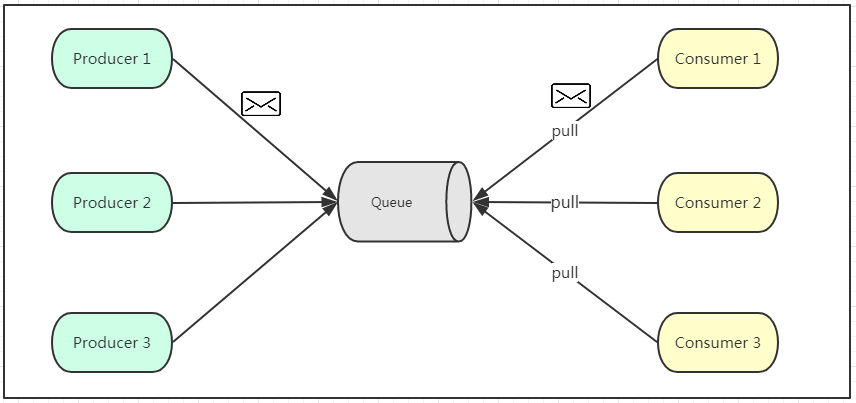 如上图所示,点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制。但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
如上图所示,点对点模式通常是基于拉取或者轮询的消息传送模型,这个模型的特点是发送到队列的消息被一个且只有一个消费者进行处理。生产者将消息放入消息队列后,由消费者主动的去拉取消息进行消费。点对点模型的的优点是消费者拉取消息的频率可以由自己控制。但是消息队列是否有消息需要消费,在消费者端无法感知,所以在消费者端需要额外的线程去监控。
发布订阅模式
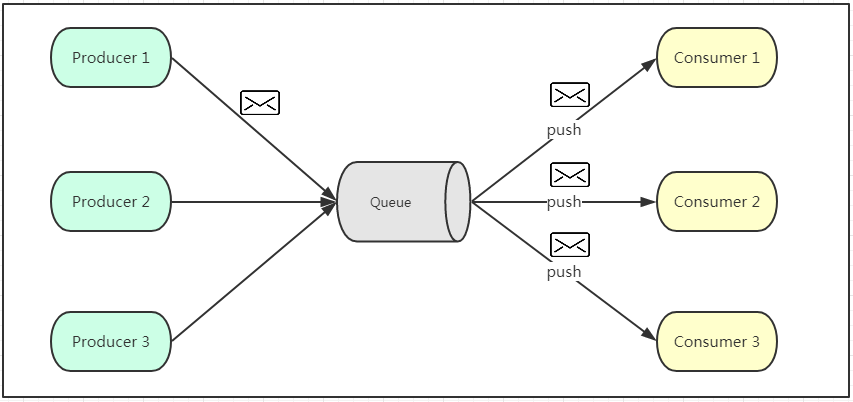 发布订阅模式是一个基于消息送的消息传送模型,改模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,但消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!
发布订阅模式是一个基于消息送的消息传送模型,改模型可以有多种不同的订阅者。生产者将消息放入消息队列后,队列会将消息推送给订阅过该类消息的消费者(类似微信公众号)。由于是消费者被动接收推送,所以无需感知消息队列是否有待消费的消息!但是consumer1、consumer2、consumer3由于机器性能不一样,所以处理消息的能力也会不一样,但消息队列却无法感知消费者消费的速度!所以推送的速度成了发布订阅模模式的一个问题!
二、Kafka服务搭建
Kafka 依赖于 ZooKeeper 来管理集群的元数据和协调功能。为了方便学习采用docker-compose部署,新建docker-compose.yml文件。
version: '3'
services:
zookeeper:
image: 'zookeeper:latest'
container_name: 'zookeeper'
ports:
- '2181:2181'
kafka:
image: 'wurstmeister/kafka:latest'
container_name: 'kafka'
ports:
- '9092:9092'
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENERS: PLAINTEXT://:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://ip:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_HEAP_OPTS: "-Xmx256M -Xms256M"
depends_on:
- zookeeper
使用命令启动
docker-compose up -d三、SpringBoot整合
pom文件引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>修改application.yml配置文件
spring:
application:
name: demo-kafka
kafka:
# 指定 Kafka 集群的地址和端口
bootstrap-servers: ip:9092
consumer:
# 设置消费者所属的消费者组的 ID,可以用来实现负载均衡和消息分区的协调。
group-id: 1
# 设置是否启用自动提交消费位移。如果设置为 true,则消费者会自动提交位移;如果设置为 false,则需要手动管理位移的提交。
enable-auto-commit: true
# 设置自动提交消费位移的时间间隔,例如 "100ms"。
auto-commit-interval: 100ms
properties:
# 设置会话超时时间,即在此时间内,消费者没有向 Kafka 服务器发送心跳请求,则被认为失去连接,默认为 15000 毫秒
session.timeout.ms: 15000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 设置当消费者加入消费者组时或位移无效的情况下,从何处开始消费消息。"earliest" 表示从最早的可用消息开始消费,"latest" 表示从最新的消息开始消费。
auto-offset-reset: earliest
producer:
# 设置生产者在发生可重试的异常时尝试发送消息的最大次数,设置为 0 表示不进行重试。
retries: 0
# :设置生产者发送到 Kafka 的批量消息的大小,达到指定大小后会触发批量发送。
batch-size: 16384
# 设置生产者用于缓冲等待发送的消息的总内存大小。
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer构建生产者
@Slf4j
@Component
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
/**
* 发送消息
*
* @param topic 话题
* @param message 消息
*/
public void sendMessage(String topic, String message) {
log.info("发送主题:{}发送内容:{}", topic, message);
kafkaTemplate.send(topic, message);
}
}构建消费者
@Slf4j
@Component
public class KafkaConsumer {
/**
* 接收消息
*
* @param message 消息
*/
@KafkaListener(topics = "my-first-topic")
public void receiveMessage(String message) {
// 处理接收到的消息逻辑
log.info("接受消息:{}", message);
}
}四、总结
基本概念和简单整合使用,待深入了解。



